Introduction
For progressive neurodegenerative diseases, early and accurate diagnosis is key to effectively developing and using new interventions. This early detection paradigm aims to identify, analyze, and prevent or manage the disease before the patient recognizes signs and symptoms while the disease process is most amenable to intervention.
Methods
This study was done in collaboration with the Accelerating Medicines Partnership in Parkinson’s disease (AMP PD) initiative as well as the Global Parkinson’s Genetics Program (GP2) initiative. Data used in the preparation of this article were obtained from the AMP PD Knowledge Platform. For up-to-date information on the study, please visit https://www.amp-pd.org. All subjects provided written informed consent for their participation in the respective cohorts. Details on how the data from the respective cohorts were acquired can be found in the Acknowledgements section. The study design and data-sharing agreement was a collaboration between AMP PD and NIH and is in accordance with NIH standard ethical approval. All study participants involved in the AMP PD initiative have provided their informed consent for their data to be used for studies to their respective cohorts.
Results
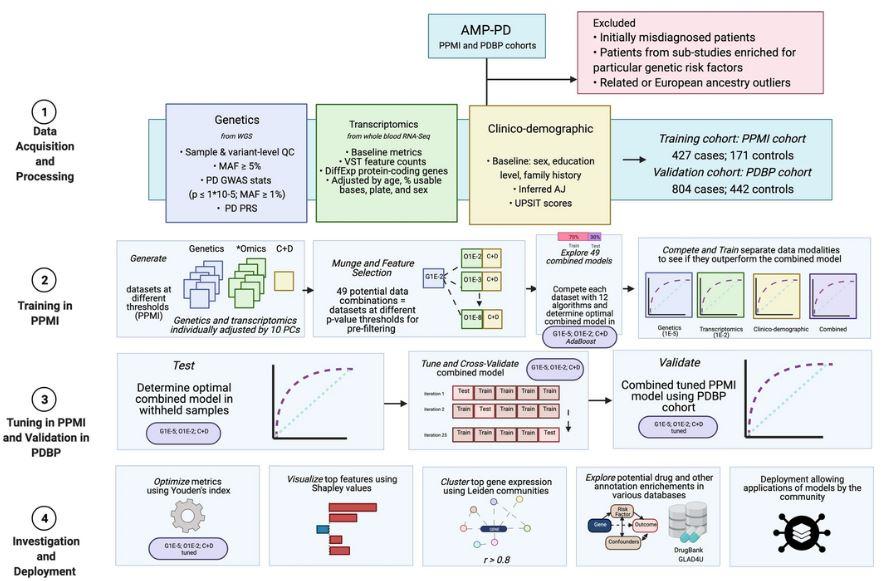
We have shown that integrating multiple modalities improved model performance in predicting PD diagnosis in a mixed population of cases and controls. For a summary of basic clinical and demographic features, please refer to Table 1 and for a summary of the analysis, please refer to Fig. 1. Additional information in regards to cohorts and interpretation for ML metrics and models are included in Supplementary Notes 2, 3. Our multi-modality model showed a higher area under the curve (AUC; 89.72%) than just the clinico-demographic data available prior to neurological assessment (87.52%), the genetics-only model from genome sequencing data and polygenic risk score (PRS; 70.66%), or the transcriptomics-only model from genome-wide whole blood RNA sequencing data (79.73%) in withheld PPMI samples (see Table 2 and Fig. 2 for summaries). This model’s performance improved after tuning, described below and in Table 3, where the mean AUC metric in the untuned model in PPMI is 80.75 with a standard deviation of 8.84 (range = 69.44–88.51) and the mean AUC at tuning in PPMI is 82.17 with a standard deviation of 8.96 (range = 70.93–90.17). Similar improvements can be seen when this model is validated in the PDBP dataset (AUC from the combined modality model at 83.84% before tuning) detailed in Table 4 and Fig. 3. Additionally, the multimodal model also had the lowest false positive and false negative rates compared to other models, only focusing on a single modality, in both the withheld test set in PPMI and in the PDBP validation set. Thus, moving from single to multiple data modalities yielded better results in not only AUC but across all performance metrics.
Source: https://www.nature.com/articles/s41531-022-00288-w#Sec2
DOI: https://doi.org/10.1038/s41531-022-00288-w